On This Page
High Availability
Overview
TOS Aurora has built-in support to run in high availability mode, using a redundancy mechanism, in which your data is kept up-to-date on three nodes (servers) simultaneously. On failure of any one of them, the up-to-date data on the other data nodes will be available. A short period of downtime may occur, depending on the type of services running on the failed node, after which TOS will continue running. The terms high availability and HA are used interchangeably. High Availability can only be installed on a single site.
Do not use HA failover for either maintenance purposes or for periodic rebooting. Such actions must be done in a controlled manner, as described in Cluster Node Maintenance.
If two of the three data nodes are down, the entire cluster will fail.
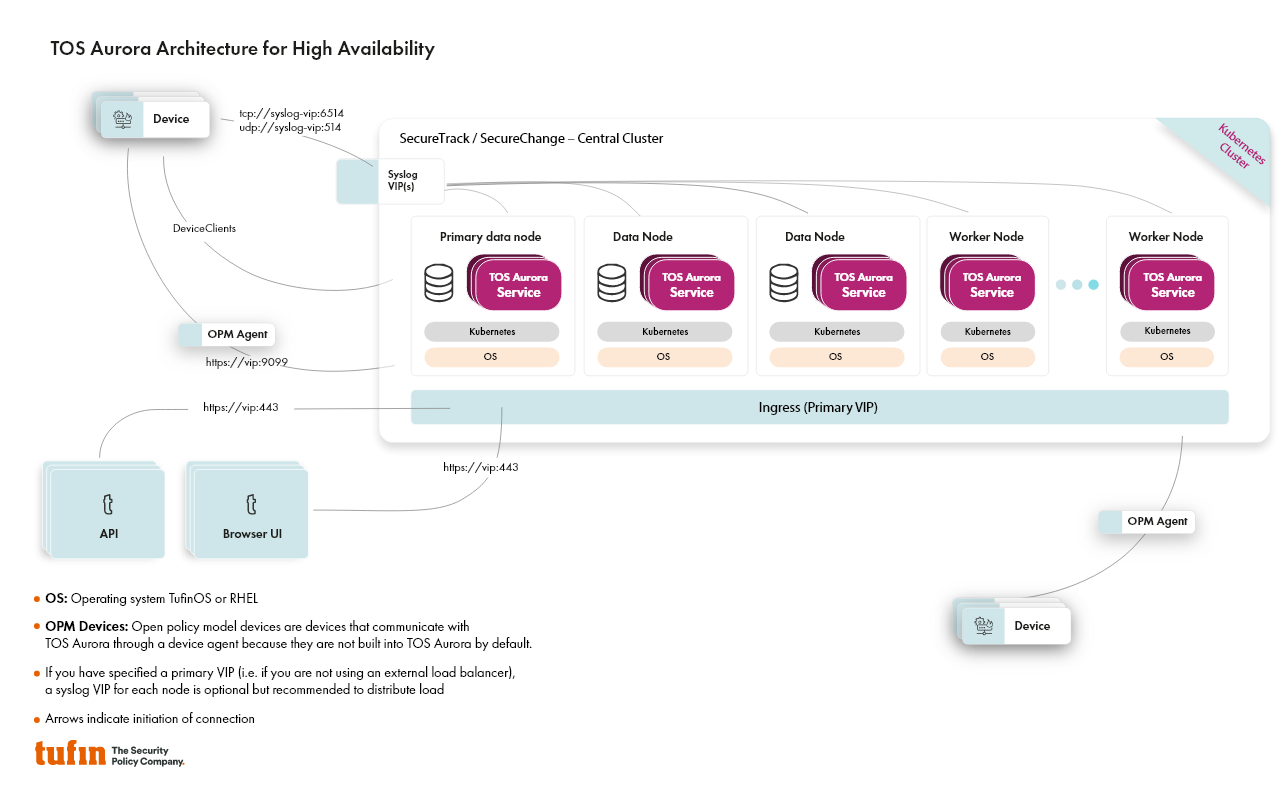
Architecture
High availability requires three data nodes in the cluster: The primary data node and two additional data nodes. Worker nodes are not required for high availability.
An odd number of nodes is a widely accepted high availability best practice. The odd number is required due to a quorum-based election mechanism. With this mechanism, a “leader” node is automatically elected from among the three data nodes in the cluster. The leader node manages the cluster and updates the other two data nodes with any changes. The leader needs a majority of the nodes (two) to be elected in order to prevent a split-brain scenario in which two different nodes are elected as leader, resulting in data corruption.
In addition, with two data nodes, if the workload is split between both nodes, failure of one node requires that the second node be able to handle the workload of the entire cluster, requiring the resource usage on any given node to be less than 50%. With three data nodes, resource usage is split more evenly, during the event of a node failure.
Data is replicated across all three data nodes, and they both store data and run data services in the cluster at any given time.
Services are automatically distributed across the different nodes (data and worker) in the cluster according to their configuration and available resources per node.
Primary Data Node
There is no difference between the primary data node and the other two data nodes when it comes to high availability functionalities.
However, the primary data node does have some unique roles:
-
You can only make changes to the cluster using CLI commands from the primary data node.
-
Backups are saved on the primary data node.
You can change one of the additional data nodes to the primary data node using the CLI command: tos cluster node set-primary
Initialization
After the additional data nodes are added, and HA is enabled, TOS Aurora will begin changing the cluster configuration from a standard configuration to a high availability configuration. During this time, TOS will not be operational. The expected initial downtime depends on the hardware performance – up to one hour.
After HA is enabled, the system will begin to replicate data. During this time TOS will be operational, but the high availability will not be fully functional until all data has been replicated. The amount of time it takes to replicate all data will depend on the volume of the data being replicated.
Multiple Sites
For high availability to work, TOS Aurora needs to be deployed on a single site.
Deploying on two sites would result in one site having two data nodes, and the other having one data node - due to the requirement for three data nodes. If the site with two data nodes fails, the entire cluster will fail, as the data node on the other site has no majority. Therefore, there is no redundancy between the sites.
In addition, the cluster is very sensitive to latency, and all the nodes have to be connected to the same L2 network and share the same subnet.
Remote Collectors
Remote collectors cannot be run under high availability, however they can be connected to a central cluster that is running under high availability.
Cloud Deployments
High availability is not supported for TOS Aurora deployed on Azure, AWS, or GCP.
Prerequisites
-
You will need two additional machines, one for each data node to be added to the cluster, making three in total, including the primary data node.
-
After adding the first new data node, proceed immediately to add the second; running on only two data nodes (i.e. primary data node and one additional data node only) will not allow high availability to be enabled and will make the cluster unstable.
-
All the nodes in the cluster need to be connected to the same L2 network and share the same subnet.
-
Each machine requires:
-
The same resources as allocated to your primary data node.
-
Allocation of a dedicated static IP address.
-
A supported operating system:
-
TufinOS 4.30
-
TufinOS 3.80, 3.81, 3.90, 3.100, 3.110
-
Red Hat Enterprise Linux 8.6, 8.8, or 8.9
-
Red Hat Enterprise Linux 8.10
-
Rocky Linux 8.10
-
-
-
Supported Tufin Appliances:
-
Gen 4: T-1200 and T-800
-
Gen 3.5:
-
T-1100 XL: Requires splitting RAID
-
T-1100: Only as a worker node, or as a data node for small size customers only.
-
-
-
Supported non-Tufin VMs/Servers: The hardware requirements for high availability are identical to the hardware requirements for a standard TOS Aurora configuration. This is determined by your system size. For more information, see Calculate System Size for a Clean Install .
-
If you have any Tufin extensions and you have migrated from TOS Classic, you must install them before switching to HA.
Enabling High Availability
-
Prepare two new machines with the operating system on your preferred platform.
If you are going to install TOS on a VM we strongly recommend partitioning directory /var to a separate, dedicated disk before installing the operating system. If this is not done, performance may be affected. For TufinOS, additional steps are required after installing the operating system. -
For each new machine, add the node with a role of 'data'.
-
On the primary data node:
Replication of data will commence. The time to completion will vary depending on the size of your database.
On completion, TOS Aurora will be in high availability mode.
-
Verify that HA is active by running sudo tos status.
-
We recommend defining a notification to inform you in the event of a change in the health of your cluster - see TOS Monitoring.
You are now in HA mode.
When Failover Occurs
Failover occurs when one of the data nodes fails. When failover occurs your system will continue running, as the other two data nodes will continue replicating data until the third one can be brought back online. However, some downtime should be expected. The failover impact and downtime depends on the:
-
Services running on the failed data node.
For example: Some services in TOS Aurora have a single service instance. When the data node fails, these services automatically restart on one of the other nodes. This can take around 15 minutes.
-
Current role of the failed data node in the cluster
-
Database size
-
Current load on the system
During failover:
-
If you have set up a notification for this event, it will be sent immediately.
-
TOS Aurora will continue to run with two data nodes.
-
The high availability status of the cluster will be impaired. Any additional data node failure will bring the cluster down. Therefore if one of the data nodes fails, it is crucial that you fix the issue as soon as possible.
-
If the failed data node is restored to a fully operational state, high availability will automatically return to full functionality.
-
If the failed node cannot be restored to a fully operational state with the same network properties, it must be replaced with another as soon as possible, to restore the high availability environment.
-
Run sudo tos cluster node list. This will show you which node has failed.
-
Prepare a new machine on your preferred platform.
-
If the failed node was the primary data node, select a new primary data node from one of the remaining data nodes by running sudo tos cluster node set-primary on the selected node.
-
Replace the failed node using sudo tos cluster node replace with the --force flag.
-
-
Verify that high availability has been restored by running the commands:
Disabling High Availability
-
On the primary data node:
--forceshould be used only if the cluster status is not healthy - see sudo tos status.On completion:
-
Replication of data to the additional data nodes will cease.
-
Data nodes other than the primary data node will contribute very little to the running of the cluster and we recommend removing them using sudo tos cluster node remove.
-
Verify that HA is no longer active by running sudo tos status on the primary data node.
-
