On This Page
Update TufinOS 3.x to 3.110
-
The TufinOS 3 operating system reached EOL (end of life) on June 30, 2024 and is no longer supported. The final version - TufinOS 3.110 - was released in December 2023. If you are still running on TufinOS 3, we recommend upgrading to TufinOS 4 to get the benefit of the latest security patches.
-
TufinOS 4 does not support TOS releases earlier than R22-2 so if you are still running R22-1 or earlier, you must upgrade TOS before upgrading to TufinOS 4.
Overview
This procedure is for updating TufinOS 3 to the latest version.
TufinOS updates are additions to the current version of the operating system. Unlike upgrades, where you replace the operating system completely, an update is used for enhancing TufinOS with the latest security and performance features as well as address any issues in order to provide a better working experience.
This procedure does not require reinstalling TOS.
The type of procedure you need to perform will depend on your deployment:
-
High Availability:
-
Without downtime - Update the worker nodes, and then update TufinOS on each data node separately. For more information on HA, see High Availability.
After updating a data node, run tos status and check if the System Status is ok and all the items listed under Components appear as ok. If this is not the case, wait for the database to sync before proceeding to update the next node. -
With downtime - Power down TOS on all nodes in the cluster and then proceed to update TufinOS on all your nodes.
-
-
Single data node cluster: First update the worker nodes and then update the data node. During the update itself, there will be some downtime as all TOS processes will need to be stopped and then restarted.
-
High Availability + Remote Collector clusters:
-
Central Cluster - See High Availability bullet above
-
Remote Collector Clusters - First update the worker nodes, and then update TufinOS on the data node. Repeat for each remote cluster. For more information on Remote Collector clusters, see Remote Collectors.
High availability is not supported for Remote Collector clusters. -
-
Single data node cluster + Remote Collector clusters: First update the central cluster: worker nodes and then data node. Afterwards, repeat for each Remote Collector cluster
Preliminary Preparations
-
 Verify that your deployment is compatible with TufinOS 3.110
Verify that your deployment is compatible with TufinOS 3.110
-
Check your current TufinOS version:
Your TufinOS release appears in the output. If the command is not recognized, you have a non-TufinOS operating system and cannot update using this procedure.
- Review the compatibility and requirements for TufinOS 3.110 and verify that you can perform the update.
-
-
Check the cluster health.
-
On the primary data node, check the following status.
-
On the same node or nodes, check the TOS status.
In the output under the line k3s.service - Aurora Kubernetes, two lines should appear - Loaded... and Active... similar to the example below. If they appear, continue with the next step, otherwise contact Tufin Support for assistance.
Example output:
[<ADMIN> ~]$ sudo systemctl status k3s [root@TufinOS ~]# systemctl status k3s Redirecting to /bin/systemctl status k3s.service ● k3s.service - Aurora Kubernetes Loaded: loaded (/etc/systemd/system/k3s.service; enabled; vendor preset: disabled) Active: active (running) since Tue 2021-08-24 17:14:38 IDT; 1 day 18h ago Docs: https://k3s.io Process: 1241 ExecStartPre=/sbin/modprobe overlay (code=exited, status=0/SUCCESS) Process: 1226 ExecStartPre=/sbin/modprobe br_netfilter (code=exited, status=0/SUCCESS) Main PID: 1250 (k3s-server) Tasks: 1042 Memory: 2.3GIn the output, if the System Status is Ok and all the items listed under Components appear as ok, continue with the next steps. Otherwise contact Tufin Support for assistance.
Example output:
[<ADMIN> ~]$ sudo tos status Tufin Orchestration Suite 2.0 System Status: Ok System Mode: Multi Node Nodes: 1 Master, 1 Worker. Total 2 nodes. Nodes are healthy. Components: Node: Ok Cassandra: Ok Mongodb: Ok Mongodb_sc: Ok Nats: Ok Neo4j: Ok Postgres: Ok Postgres_sc: Ok
-
Update TufinOS
Update TufinOS in a High Availability Cluster
-
Update without downtime
-
Update worker nodes
-
Go to the Download Center, click on the 3.110 update package , and choose to copy a link.
-
On the target machine, switch to the root user
-
Go to /opt/misc.
-
Run the screen command.
-
Download the installation package.
-
Extract the TufinOS image from its archive.
The run file name includes the release, version, build number, and type of installation.
TufinOS update file example: TufinOS-4.20-639387-x86_64-8.8-Final-Update.run.tgz
-
Verify the integrity of the TufinOS installation package.
[<ADMIN> ~]# sha256sum -c TufinOS-X.XX-XXXXXX-x86_64-Final-Update.sha256sha256sum -c TufinOS-X.XX-XXXXXX-x86_64-Final-Update.sha256The output should return OK
-
Execute the TufinOS update file:
-
When prompted to continue the update, enter yes.
Do not interrupt the update process. Wait until the successful completion message appears.
-
After the update is complete, reboot the node:
-
Log in to the primary data node.
Where <LINK> is the link you copied from the Download Center.
-
-
Update data nodes
Repeat this procedure for all three data nodes.
After updating a data node, run tos status and check if the System Status is ok and all the items listed under Components appear as ok. If this is not the case, wait for the database to sync before proceeding to update the next node.-
If you are going to perform this procedure over multiple maintenance periods, create a new backup each time.
-
Create the backup using tos backup create:
-
You can check the backup creation status using tos backup status, which shows the status of backups in progress. Wait until completion before continuing.
-
Run the following command to display the list of backups saved on the node:
-
Check that your backup file appears in the list, and that the status is "Completed".
-
Run the following command to export the backup to a file:
-
If your backup files are saved locally:
-
Run sudo tos backup export to save your backup file from a TOS backup directory as a single
.gzipfile. If there are other backups present, they will be included as well. -
Transfer the exported
.gzipfile to a safe, remote location.Make sure you have the location of your backups safely documented and accessible, including credentials needed to access them, for recovery when needed.
After the backup is exported, we recommend verifying that the file contents can be viewed by running the following command:
-
Example output:
[%=Local.admin-prompt% sudo tos backup create [Aug 23 16:18:42] INFO Running backup Backup status can be monitored with "tos backup status"
Example output:
[<ADMIN> ~]$ sudo tos backup status Found active backup "23-august-2021-16-18"
Example output:
[<ADMIN> ~]$ sudo tos backup list ["23-august-2021-16-18"] Started: "2021-08-23 13:18:43 +0000 UTC" Completed: "N/A" Modules: "ST, SC" HA mode: "false" TOS release: "21.2 (PGA.0.0) Final" TOS build: "21.2.2100-210722164631509" Expiration Date: "2021-09-22 13:18:43 +0000 UTC" Status: "Completed"
The command creates a single backup file.
[<ADMIN> ~]$ sudo tos backup export [Aug 23 16:33:42] INFO Preparing target dir /opt/tufin/backups [Aug 23 16:33:42] INFO Compressing... [Aug 23 16:33:48] INFO Backup exported file: /opt/tufin/backups/backup-21-2-pga.0.0-final-20210823163342.tar.gzip [Aug 23 16:33:48] INFO Backup export has completed
-
-
Go to the Download Center, click on the 3.110 update package , and choose to copy a link.
-
On the target machine, switch to the root user
-
Go to /opt/misc.
-
Run the screen command.
-
Download the installation package.
-
Extract the TufinOS image from its archive.
The run file name includes the release, version, build number, and type of installation.
TufinOS update file example: TufinOS-4.20-639387-x86_64-8.8-Final-Update.run.tgz
-
Verify the integrity of the TufinOS installation package.
[<ADMIN> ~]# sha256sum -c TufinOS-X.XX-XXXXXX-x86_64-Final-Update.sha256sha256sum -c TufinOS-X.XX-XXXXXX-x86_64-Final-Update.sha256The output should return OK
-
Get the name of the node you want to update by running the following command on any of the data nodes.
A list of nodes which currently exist in the cluster is displayed.
-
In the output, note the name of the node you want to update.
-
Run the following command:
-
Execute the TufinOS update file:
-
When prompted to continue the update, enter yes.
Do not interrupt the update process. Wait until the successful completion message appears.
-
After the update is complete, run the following command:
-
After the update is complete, reboot the node:
-
Log in to the primary data node.
-
Check the TOS status.
-
Run the following command on the node you updated
-
In the output, check if the System Statusok and all the items listed under Components appear as ok. If this is not the case, contact Tufin Support for assistance.
Example output:
[<ADMIN> ~]$ sudo tos status [Aug 23 16:34:12] INFO Checking cluster health status TOS Aurora System Status: "Ok" Cluster Status: Status: "Ok" Mode: "High Availability" Nodes: - ["User1"] Type: "Primary" Status: "Ok" Disk usage: - ["/opt"] Status: "Ok" Usage: 25% - ["User2"] Type: "Ha Data Node" Status: "Ok" Disk usage: - ["/opt"] Status: "Ok" Usage: 7.6% - ["User3"] Type: "Ha Data Node" Status: "Ok" Disk usage: - ["/opt"] Status: "Ok" Usage: 7.4% Databases: - ["cassandra"] Status: "Ok" - ["kafka"] Status: "Ok" - ["mongodb"] Status: "Ok" - ["mongodb_sc"] Status: "Ok" - ["ongDb"] Status: "Ok" - ["postgres"] Status: "Ok" - ["postgres_sc"] Status: "Ok" Backup Storage: Location: "Local s3:http://minio.default.svc:9000/velerok8s/restic/default " Status: "Ok" Last compatibe healthy backup Timestamp: 2023-08-21 12:01:07 +0000 UT Registry: Expiration ETA: 817 days Status: "Ok"
-
Where <LINK> is the link you copied from the Download Center.
where <NODENAME> is the name of the node you want to update.
where <NODENAME> is the name of the node you want to update.
All TOS processes will be restarted on all the data nodes in the cluster, and you will be able to resume using TOS.
-
-
-
Update with downtime
-
If you are going to perform this procedure over multiple maintenance periods, create a new backup each time.
-
Create the backup using tos backup create:
-
You can check the backup creation status using tos backup status, which shows the status of backups in progress. Wait until completion before continuing.
-
Run the following command to display the list of backups saved on the node:
-
Check that your backup file appears in the list, and that the status is "Completed".
-
Run the following command to export the backup to a file:
-
If your backup files are saved locally:
-
Run sudo tos backup export to save your backup file from a TOS backup directory as a single
.gzipfile. If there are other backups present, they will be included as well. -
Transfer the exported
.gzipfile to a safe, remote location.Make sure you have the location of your backups safely documented and accessible, including credentials needed to access them, for recovery when needed.
After the backup is exported, we recommend verifying that the file contents can be viewed by running the following command:
-
Example output:
[%=Local.admin-prompt% sudo tos backup create [Aug 23 16:18:42] INFO Running backup Backup status can be monitored with "tos backup status"
Example output:
[<ADMIN> ~]$ sudo tos backup status Found active backup "23-august-2021-16-18"
Example output:
[<ADMIN> ~]$ sudo tos backup list ["23-august-2021-16-18"] Started: "2021-08-23 13:18:43 +0000 UTC" Completed: "N/A" Modules: "ST, SC" HA mode: "false" TOS release: "21.2 (PGA.0.0) Final" TOS build: "21.2.2100-210722164631509" Expiration Date: "2021-09-22 13:18:43 +0000 UTC" Status: "Completed"
The command creates a single backup file.
[<ADMIN> ~]$ sudo tos backup export [Aug 23 16:33:42] INFO Preparing target dir /opt/tufin/backups [Aug 23 16:33:42] INFO Compressing... [Aug 23 16:33:48] INFO Backup exported file: /opt/tufin/backups/backup-21-2-pga.0.0-final-20210823163342.tar.gzip [Aug 23 16:33:48] INFO Backup export has completed
-
-
Shut down TOS.
-
Run the command:
This process may take time.
- Check that all processes have been stopped successfully. Run the command:
-
Wait until all the pods, with the exception of the service controller, ps-proxy, and reportpack pods, have disappeared from the list or reached a status of Completed. The service controller, ps-proxy, and reportpack pods which can continue running.
All TOS processes are now stopped on all the data nodes in the cluster.
A list of all pods is displayed.
Example
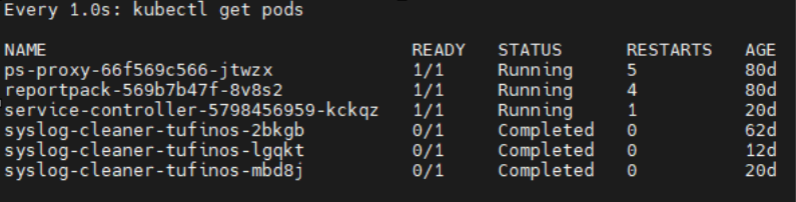
-
-
Repeat steps 4-13 for each node in the cluster.
-
Go to the Download Center, click on the 3.110 update package , and choose to copy a link.
-
On the target machine, switch to the root user
-
Go to /opt/misc.
-
Run the screen command.
-
Download the installation package.
-
Extract the TufinOS image from its archive.
The run file name includes the release, version, build number, and type of installation.
TufinOS update file example: TufinOS-4.20-639387-x86_64-8.8-Final-Update.run.tgz
-
Verify the integrity of the TufinOS installation package.
[<ADMIN> ~]# sha256sum -c TufinOS-X.XX-XXXXXX-x86_64-Final-Update.sha256sha256sum -c TufinOS-X.XX-XXXXXX-x86_64-Final-Update.sha256The output should return OK
-
Execute the TufinOS update file:
-
When prompted to continue the update, enter yes.
Do not interrupt the update process. Wait until the successful completion message appears.
-
After the update is complete, reboot the node:
-
After updating all data nodes, log in to the primary data node.
-
Restart TOS on the primary data node:
Where <LINK> is the link you copied from the Download Center.
All TOS processes will be restarted on all the data nodes in the cluster, and you will be able to resume using TOS.
-
Update TufinOS in Single Data Node Cluster
-
Update worker nodes
-
Go to the Download Center, click on the 3.110 update package , and choose to copy a link.
-
On the target machine, switch to the root user
-
Go to /opt/misc.
-
Run the screen command.
-
Download the installation package.
-
Extract the TufinOS image from its archive.
The run file name includes the release, version, build number, and type of installation.
TufinOS update file example: TufinOS-4.20-639387-x86_64-8.8-Final-Update.run.tgz
-
Verify the integrity of the TufinOS installation package.
[<ADMIN> ~]# sha256sum -c TufinOS-X.XX-XXXXXX-x86_64-Final-Update.sha256sha256sum -c TufinOS-X.XX-XXXXXX-x86_64-Final-Update.sha256The output should return OK
-
Execute the TufinOS update file:
-
When prompted to continue the update, enter yes.
Do not interrupt the update process. Wait until the successful completion message appears.
-
After the update is complete, reboot the node:
-
Log in to the primary data node.
Where <LINK> is the link you copied from the Download Center.
-
-
Update primary data node
-
If you are going to perform this procedure over multiple maintenance periods, create a new backup each time.
-
Create the backup using tos backup create:
-
You can check the backup creation status using tos backup status, which shows the status of backups in progress. Wait until completion before continuing.
-
Run the following command to display the list of backups saved on the node:
-
Check that your backup file appears in the list, and that the status is "Completed".
-
Run the following command to export the backup to a file:
-
If your backup files are saved locally:
-
Run sudo tos backup export to save your backup file from a TOS backup directory as a single
.gzipfile. If there are other backups present, they will be included as well. -
Transfer the exported
.gzipfile to a safe, remote location.Make sure you have the location of your backups safely documented and accessible, including credentials needed to access them, for recovery when needed.
After the backup is exported, we recommend verifying that the file contents can be viewed by running the following command:
-
Example output:
[%=Local.admin-prompt% sudo tos backup create [Aug 23 16:18:42] INFO Running backup Backup status can be monitored with "tos backup status"
Example output:
[<ADMIN> ~]$ sudo tos backup status Found active backup "23-august-2021-16-18"
Example output:
[<ADMIN> ~]$ sudo tos backup list ["23-august-2021-16-18"] Started: "2021-08-23 13:18:43 +0000 UTC" Completed: "N/A" Modules: "ST, SC" HA mode: "false" TOS release: "21.2 (PGA.0.0) Final" TOS build: "21.2.2100-210722164631509" Expiration Date: "2021-09-22 13:18:43 +0000 UTC" Status: "Completed"
The command creates a single backup file.
[<ADMIN> ~]$ sudo tos backup export [Aug 23 16:33:42] INFO Preparing target dir /opt/tufin/backups [Aug 23 16:33:42] INFO Compressing... [Aug 23 16:33:48] INFO Backup exported file: /opt/tufin/backups/backup-21-2-pga.0.0-final-20210823163342.tar.gzip [Aug 23 16:33:48] INFO Backup export has completed
-
-
Shut down TOS.
-
Run the command:
This process may take time.
- Check that all processes have been stopped successfully. Run the command:
-
Wait until all the pods, with the exception of the service controller, ps-proxy, and reportpack pods, have disappeared from the list or reached a status of Completed. The service controller, ps-proxy, and reportpack pods which can continue running.
All TOS processes are now stopped on all the data nodes in the cluster.
A list of all pods is displayed.
Example
-
-
Go to the Download Center, click on the 3.110 update package , and choose to copy a link.
-
On the target machine, switch to the root user
-
Go to /opt/misc.
-
Run the screen command.
-
Download the installation package.
-
Extract the TufinOS image from its archive.
The run file name includes the release, version, build number, and type of installation.
TufinOS update file example: TufinOS-4.20-639387-x86_64-8.8-Final-Update.run.tgz
-
Verify the integrity of the TufinOS installation package.
[<ADMIN> ~]# sha256sum -c TufinOS-X.XX-XXXXXX-x86_64-Final-Update.sha256sha256sum -c TufinOS-X.XX-XXXXXX-x86_64-Final-Update.sha256The output should return OK
-
Execute the TufinOS update file:
-
When prompted to continue the update, enter yes.
Do not interrupt the update process. Wait until the successful completion message appears.
-
After the update is complete, reboot the node:
-
Log in to the primary data node.
-
Restart TOS on the primary data node:
Where <LINK> is the link you copied from the Download Center.
All TOS processes will be restarted on all the data nodes in the cluster, and you will be able to resume using TOS.
-
Update TufinOS in a High Availability Cluster with Remote Collector Clusters
Follow the procedures above to update the nodes in the Central cluster and the Remote Collector clusters.
After updating all nodes:
-
Check that the Remote Collector is still connected.
-
Run the following command:
-
If the Remote Collector cluster is not connected, run the following commands to connect it to the Central cluster, where:
[<ADMIN> ~]$ sudo tos cluster connect --central-cluster-vip=CENTRAL-CLUSTER-VIP --remote-cluster-vip=REMOTE-CLUSTER-VIP --remote-cluster-name=REMOTE-CLUSTER-NAME --initial-secret=OTPsudo tos cluster connect --central-cluster-vip=CENTRAL-CLUSTER-VIP --remote-cluster-vip=REMOTE-CLUSTER-VIP --remote-cluster-name=REMOTE-CLUSTER-NAME --initial-secret=OTPwhere
Parameter
Description
Required/Optional
--central-cluster-vipExternal IP address (VIP) of your central server cluster.
Required
--remote-cluster-vipExternal IP address (VIP) of the server you want to connect (i.e. the current server).
Required --remote-cluster-nameAny alphanumeric string you choose; quotes are not used so you cannot embed spaces.
Required
--initial-secretOne-time password returned from running tos cluster generate-otp on the central server.
Required
The output shows all connected clusters.
Example output:
-
Update TufinOS in Single Data Node Cluster with Remote Collector Clusters
Follow the procedures above to update the nodes in the Central cluster and the Remote Collector clusters.
After updating all nodes:
-
Check that the Remote Collector is still connected.
-
Run the following command:
-
If the Remote Collector cluster is not connected, run the following commands to connect it to the Central cluster, where:
[<ADMIN> ~]$ sudo tos cluster connect --central-cluster-vip=CENTRAL-CLUSTER-VIP --remote-cluster-vip=REMOTE-CLUSTER-VIP --remote-cluster-name=REMOTE-CLUSTER-NAME --initial-secret=OTPsudo tos cluster connect --central-cluster-vip=CENTRAL-CLUSTER-VIP --remote-cluster-vip=REMOTE-CLUSTER-VIP --remote-cluster-name=REMOTE-CLUSTER-NAME --initial-secret=OTPwhere
Parameter
Description
Required/Optional
--central-cluster-vipExternal IP address (VIP) of your central server cluster.
Required
--remote-cluster-vipExternal IP address (VIP) of the server you want to connect (i.e. the current server).
Required --remote-cluster-nameAny alphanumeric string you choose; quotes are not used so you cannot embed spaces.
Required
--initial-secretOne-time password returned from running tos cluster generate-otp on the central server.
Required
The output shows all connected clusters.
Example output:
-
